How lnx does fuzzy searching over 5x faster with SymSpell
Full discloser, this goes is a rather general look over in the rather incredible algorithm that is SymSpell and how we implement it in lnx, that said, it's still rather long.
So one of the coolest features I ran into when developing lnx was an algorithm called SymSpell, I'll explain what it is later but as a TL;DR:
1 million times faster spelling correction & fuzzy search through Symmetric Delete spelling correction algorithm
😎 Oooh yeahhh! Now this will be interesting. But first I think we need a bit of context on why this is a big thing for typo-tolerant search.
Btw lnx (0.7.0) is out now bringing some nice QOL changes
https://github.com/lnx-search/lnx
Tolerance takes time. Literally.
Whenever you want a search engine to account for a user's typing mistakes you have to calculate the changes needed to be applied to a word to get the target word. E.g. If I want to correct Beer to Bree we have to apply two substituting.
It breaks down to:
- Beer -> Brer+1 for substituting e with r.
- Brer -> Bree +1 for substituting r with e .
You can read more Levenshtein distance here.
Now, this is a relatively simple process, the issue comes when you have millions of words to search and compare against an entire sentence. Suddenly you find yourself doing millions of iterations to achieve this typo tolerance. This is where stuff starts to get real slow, real quick when looking at bigger indexes especially if you have lots of users to search requests to.
Now, most of the time search engines employee the strategy of working out the max edit distance based on the word length, this helps relevancy by not being overly forgiving with matching similar words but also helps performance as most words will have an edit distance of 0 or 1 which saves a lot of computing than say allowing every word for a max edit distance of 2 . This equally comes as a trade-off, however, words like hello will only be given an edit distance of 0 even though a very common mistake is helo or the likes, it's also still rather slow compared to a pure full-text search.
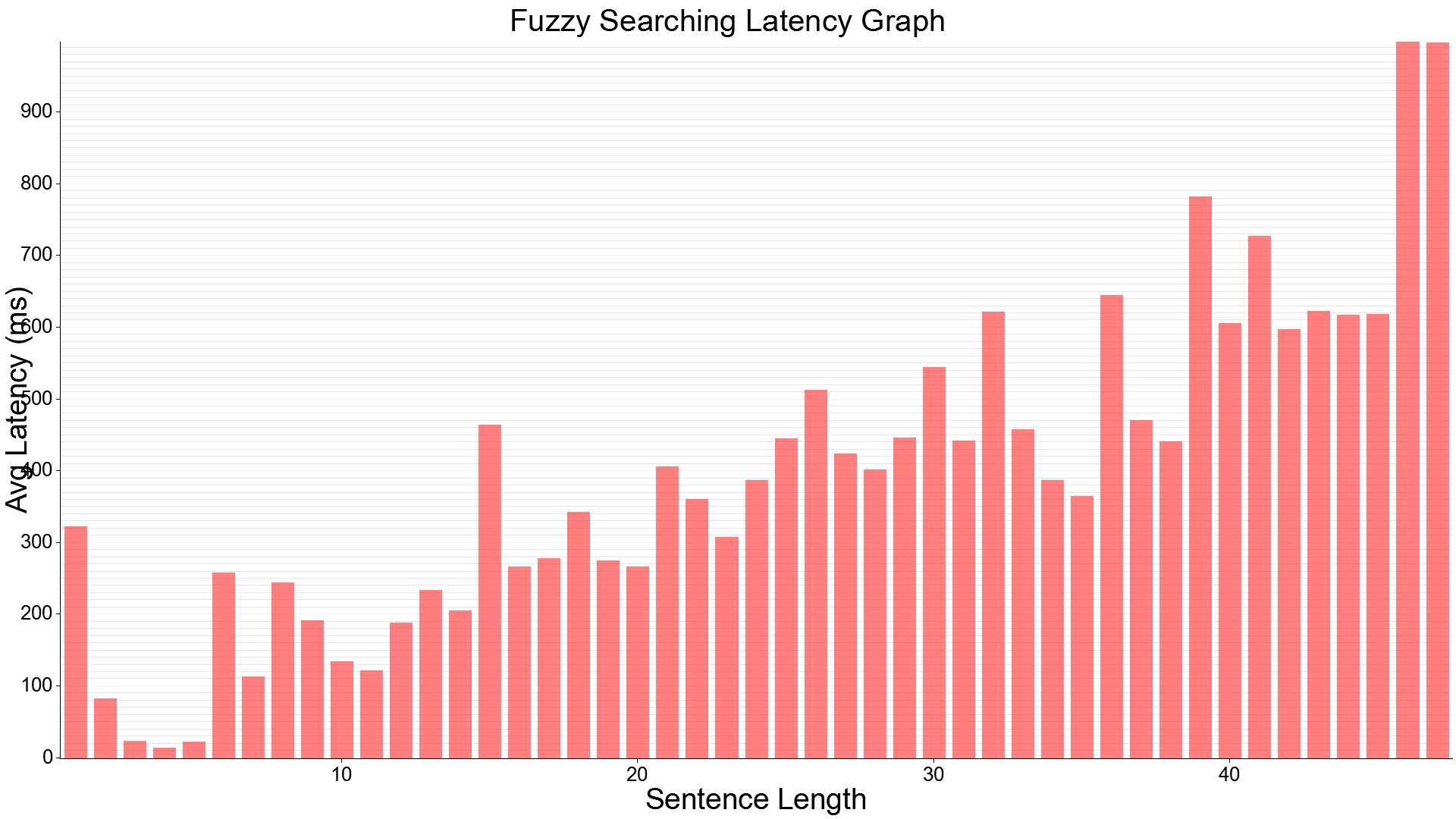
As you can see with the above image, when we grow to bigger indexes (in this case 20GB worth of text) our latencies skyrocket when running just 1 concurrent client at any one time on my local machine with a rather high 5GHz clock speed and NVMe drives.
INFO lnxcli > starting benchmark system
INFO benchmark > starting runtime with 4 threads
INFO benchmark > Service ready! Beginning benchmark.
INFO benchmark > Concurrency @ 1 clients
INFO benchmark > Searching @ 6 sentences
INFO benchmark > Mode @ Typing
INFO benchmark::sampler > General benchmark results:
INFO benchmark::sampler > Total Requests Sent: 178
INFO benchmark::sampler > Average Requests/sec: 3.17
INFO benchmark::sampler > Average Latency: 315.398876ms
INFO benchmark::sampler > Max Latency: 1.215s
INFO benchmark::sampler > Min Latency: 4ms
INFO benchmark::sampler > Stdev Latency: 284.272545ms
So we're left with three options in this scenario:
- Increase the amount of computing power of a single machine or shard search requests.
- Remove the amount of searchable text.
- Ditch typo tolerance.
As a complete side note, if you're looking to ditch typo tolerance and search massive indexes in as cost-effective a way as possible Quickwit is very cool.
Enter SymSpell
As mentioned above, most engines tend to drop performance quite rapidly the query words get bigger and/or as the amount of text to search increases, it also leads to rather large jumps in latency as we saw with the min latency being 4ms and the max being 1.2s, not great for user experience.
Now, annoyed by this, what would you do? In my case, I scoured the internet looking for any quick speedups or improved systems that everyone else has already searched for but to no avail. However, there was one that stood out (mostly from the article title of "1000x faster Spelling Correction"), SymSpell was an alternative mostly designed for things like your iPhone's spell correction system turning things like "helloworrld" into "hello world".
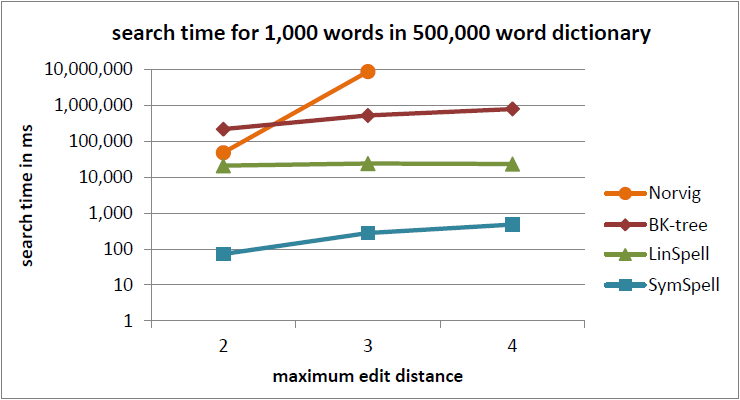
This sounds great right!? But why don't any search engines use this algorithm in place of the traditional levenshtein algorithm which currently how engines like MeiliSearch does it spell correction? To understand that we need to look a little deeper into how the algorithm itself works.
Wht teh hell is SymSpell
SymSpell breaks down into the symmetric delete spelling correction algorithm:
Generate terms with an edit distance (deletes only) from each dictionary term and add them together with the original term to the dictionary. This has to be done only once during a pre-calculation step. Generate terms with an edit distance (deletes only) from the input term and search them in the dictionary. For a word of length n, an alphabet size of a, an edit distance of 1, there will be just n deletions, for a total of n terms at search time.
For more info checkout Wolf Garbe's blog.
Overall this makes corrections much, much cheaper to do at the cost of some pre-computation and memory usage (the pre-computed dictionaries are kept in memory) however, this is what makes it hard to use in a search engine and what took so many attempts and design iterations to get it to work within lnx.
Dictionaries are bigg
Now we all know the secret sauce to how SymSpell is so fast, we have to deal with the fact that it's an issue for us as a search engine.
If we take the traditional approach of having a frequency dictionary for every language like so:
Now we run into two issues right off the bat with this approach:
- We need an accurate-ish dictionary for every language we want to support.
- We always have to load all the processed dictionary data into memory no matter what the data inside of the indexes is.
These are reasonable superficial issues however, after all in a server context using 1.5GB of memory isn't a massive issue, and you can always make dictionaries up from the google word frequency datasets.
The biggest issue by far is the fact that you're now correcting to a dictionary standard rather than to words inside of the index this makes for some interesting relevancy behaviour when looking at names in particular:
Take the sentence "the trumen show", you would probably expect this to be correct and match documents with words like "the truman show" assuming the name "Trumen" exists in our index (case-insensitive,) but disaster 😧 our SymSpell implementation corrects it to "the true man show" when we use an edit distance of 1+. Now, this is no fault of SymSpell, it's doing its job of segmenting the word to words that fall within the given dictionary data and are within a max edit distance of 1. The issue is we can't match relevant documents correctly when the two systems act in different ways.
Act 2: Correcting the correction behaviour
The first plan of attack was simple -> just correct the index data itself and search that then return the original text separately. Simple right?
Well yes and no, it did resolve issues like "truman" being corrected into "true man" because any words like that inside the index had then been corrected into "true man" themselves, the issue came when you tried to add data in the first place:
It's INCREDIBLY slow. For context, it takes lnx (0.7.0) about an hour or so to index all 27,000,000 documents on my computer. For this approach, I gave up trying to time it after it took longer than 4 hours. After all, lnx is designed to be fast at indexing not just searching (the idea of testing large indexes with that kind of indexing time also caused me to lose a bit of my sanity.)
A lot of this extra came from the fact that you're suddenly correcting hundreds of millions of words + indexing time which is a massive waste of resources.
Getting creative with dictionaries
After many, many workarounds attempt to use the previous system it was time to get creative.
I started using SymSpell with the mindset of using it like an autocorrect-like system correcting to valid words rather than from a search engine perspective which is: We don't care about if the words are spelt correctly, we care about matching similar words inside of the index.
When looking at it from this perspective we notice that we can create our indexes based on our index data rather than a hard-coded list. This is a relatively simple process of collecting the word frequencies of the indexed corpus itself and piping that into SymSpell. And these words well.
This solves all of our previous problems:
- We're able to generate small dictionaries for small indexes which reduces the memory consumption down to almost nothing.
- SymSpell now corrects based on the context of our index corpus correctly correcting words like "trumen" to "truman".
- It's really fast.
- If there is a correction made we're 99% sure there will be at least one match.
Implementing it into lnx
Now we know how we want to add SymSpell let's look at how we add it into lnx. (All the previous versions have been implemented in lnx at some point in time, this is just a general, clean overview of what was in reality. A lot of trial and error.)
Our word frequency system is built upon our FrequencyCounter trait.
pub(crate) trait FrequencyCounter {
fn process_sentence(&mut self, sentence: &str);
fn register(&mut self, k: String);
fn clear_frequencies(&mut self);
fn get_count(&self, k: &str) -> u32;
fn counts(&self) -> &HashMap<String, u32>;
}
The reason for this being a trait is because we have a memory layer that does the counting and processing and then a persistence layer that's in charge of persisting any changes to disk and making sure we keep the frequency in line with the index itself. I'm not going to show them here because they're quite big but they can be here in reality though, it's a pretty simple idea:
Tokenise the words, count how many times each word appears.
For SymSpell itself I considered implementing it from scratch (and might still do at some stage) but reneklacan's implementation works just fine with a bit of modification for loading a dictionary in-memory rather than from a file. We use SymSpell's lookup_compound system which does all the work for us like correction, segmentation, etc... And pretty much comes down to a simple check in the query builder:
if self.ctx.use_fast_fuzzy {
query = self.symspell.lookup_compound(&query);
}
// ...Some vauge text processing ensues
let query: Box<dyn Query> = if self.ctx.use_fast_fuzzy {
Box::new(TermQuery::new(term, IndexRecordOption::WithFreqs))
} else {
// Default fuzzy system used.
}
The full logic can be found at query.rs but in general, we're simply correcting the sentence before generating any queries then creating a set of TermQuery as opposed to using a FuzzyTermQuery
Evaluating our new setup
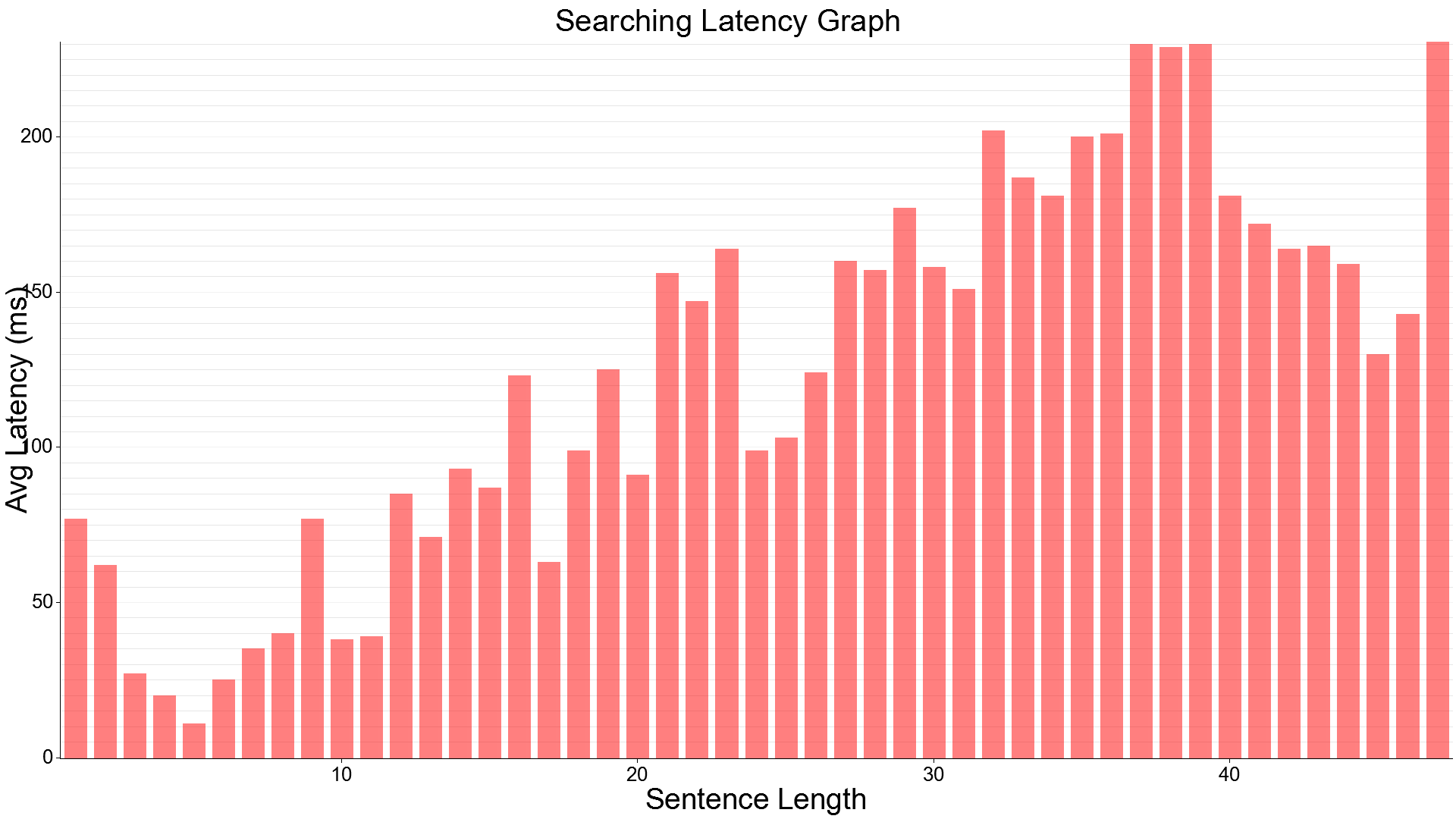
This looks promising we're running on a rather un-optimised index set with this test (mostly because I didn't feel like re-building a new index just for this graph and I think it demonstrates the point well enough.) In reality with a single client, we can fairly reasonably enjoy a search as you type experience even at 27,000,000 documents with over 20 GB of searchable text.
When we compare this against the previous fuzzy system:
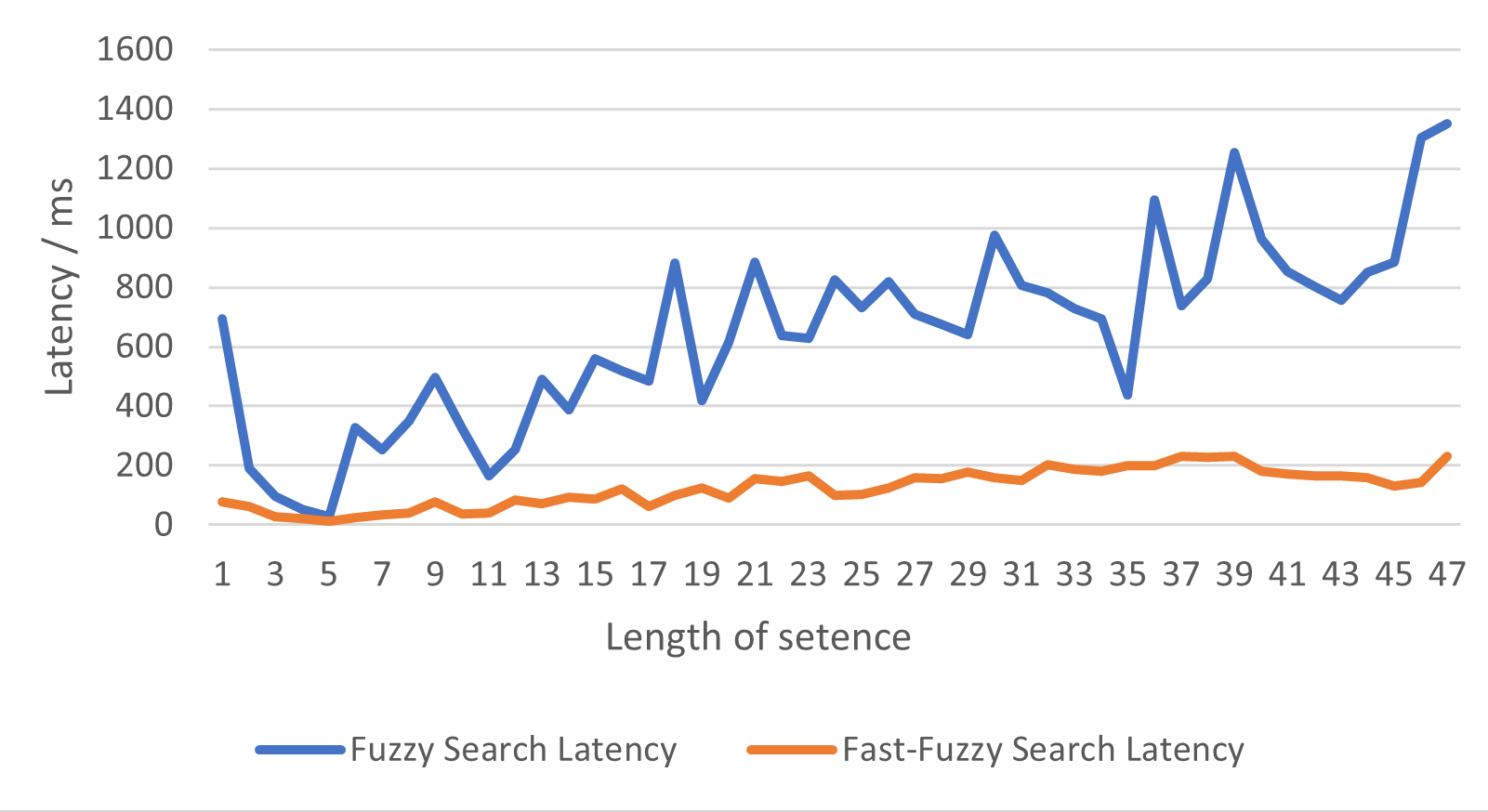
This setup with fast-fuzzy uses ~2.5GB of memory (which quickly gets paged out by the OS as most of it isn't frequently used on most queries)
Fuzzy
INFO lnxcli > starting benchmark system
INFO benchmark > starting runtime with 4 threads
INFO benchmark > Service ready! Beginning benchmark.
INFO benchmark > Concurrency @ 1 clients
INFO benchmark > Searching @ 6 sentences
INFO benchmark > Mode @ Typing
INFO benchmark::sampler > General benchmark results:
INFO benchmark::sampler > Total Requests Sent: 178
INFO benchmark::sampler > Average Requests/sec: 3.17
INFO benchmark::sampler > Average Latency: 315.398876ms
INFO benchmark::sampler > Max Latency: 1.215s
INFO benchmark::sampler > Min Latency: 4ms
INFO benchmark::sampler > Stdev Latency: 284.272545ms
Fast-Fuzzy (SymSpell)
INFO lnxcli > starting benchmark system
INFO benchmark > starting runtime with 4 threads
INFO benchmark > Service ready! Beginning benchmark.
INFO benchmark > Concurrency @ 1 clients
INFO benchmark > Searching @ 6 sentences
INFO benchmark > Mode @ Typing
INFO benchmark::sampler > General benchmark results:
INFO benchmark::sampler > Total Requests Sent: 178
INFO benchmark::sampler > Average Requests/sec: 21.09
INFO benchmark::sampler > Max Latency: 178ms
INFO benchmark::sampler > Min Latency: 1ms
INFO benchmark::sampler > Stdev Latency: 49.880349ms
Future Improvements
- Consider allowing for an edit distance of 2 for longer words like the original fuzzy system uses. I'm happy keeping a minimum edit distance of 1 for everything else as it seems to work well with relevancy and also stops the whole miss-spelling "helo" issue.
- Writing a custom SymSpell algorithm to further reduce memory consumption: Smaller hasher? Small int sizes?
- Garbage collector for handling deleted documents, as of now the system is append-only which can cause the relevancy to degrade when doing lots of updates/removals. Generally, the workaround is completely to remove and re-build the index.
Notes and disclosures
Just because this system is much faster and (generally) more consistent latency wise does not make it immune to the strain of big datasets, although this helps an incredible amount for large user-facing datasets, you will likely still want a pretty big server to deal with a large amount of throughput.
The testing and graphs shown show a small number of concurrent clients, this is because I ran a lot of these tests and the number of requests sent and latency increases dramatically the more clients/concurrency you add. Tests were run at 1, 4 and 12 concurrent clients. The comparison line graph is using 4 concurrent clients. I later ran with 12 clients but this was harder to show on a graph to things becoming more unstable.
Tests were run using the https://github.com/lnx-search/lnx-cli tool in bench mode. You're more than welcome to run these sorts of tests yourself, it took about an hour to load the full dataset up on my machine with lnx and the dataset can be found here. You can also find the sample sentences here.
Shoutouts and general gratitude for existing
- Tantivy and Quickwit search, without Tantivy, lnx wouldn't exist and even if it did would never be able to produce the same amount of performance.
- Wolf Garbe's work with the SymSpell algorithm and the amazing detail given about it.
- reneklacan for actually implementing the base of the algorithm itself.
- MeiliSearch for linking their example movies dataset that broke my implementation and relevancy tests too many times.