μpack: Faster & more flexible integer compression
Efficient integer compression is a key component of any search engine, columnar file format, OLAP workload and more. Furthermore, unlike the more generic LZ (Lempel-Ziv) family of data compressors, SIMD-based optimisations can often allow integer compression algorithms to be an order of magnitude faster, compressing and decompressing tens of GB/s of integer data on a single CPU core.
However, popular existing algorithms like Daniel Lemire's simdcomp require fixed-sized integer blocks that interleave the input integers in order to efficiently leverage SIMD instructions. As a result, byte-oriented compression algorithms like Google's Varint-GB or Daniel Lemire's Stream VByte are often used for the remainder of the integers that cannot fill the fixed-sized block, which, although incredibly fast, often has a considerably lower compression ratio.
This is where I present μpack, a bitpacking library which only requires the input memory to be padded to the 128-element block size, allowing any number of elements between 1 and 128 elements to be compressed more effectively than Stream VByte while still (de)compressing billions of integers per second.
The source code and examples are available at https://github.com/lnx-search/upack
How it works
If we attempt to pack integers naively while maintaining the order, we immediately discover that it is non-trivial to do so while also trying to maximise the performance of our routine and the SIMD operations within it.
The simdcomp library works around this issue by vertically interleaving the elements, which breaks the original ordering but significantly improves the efficiency of the SIMD operations.
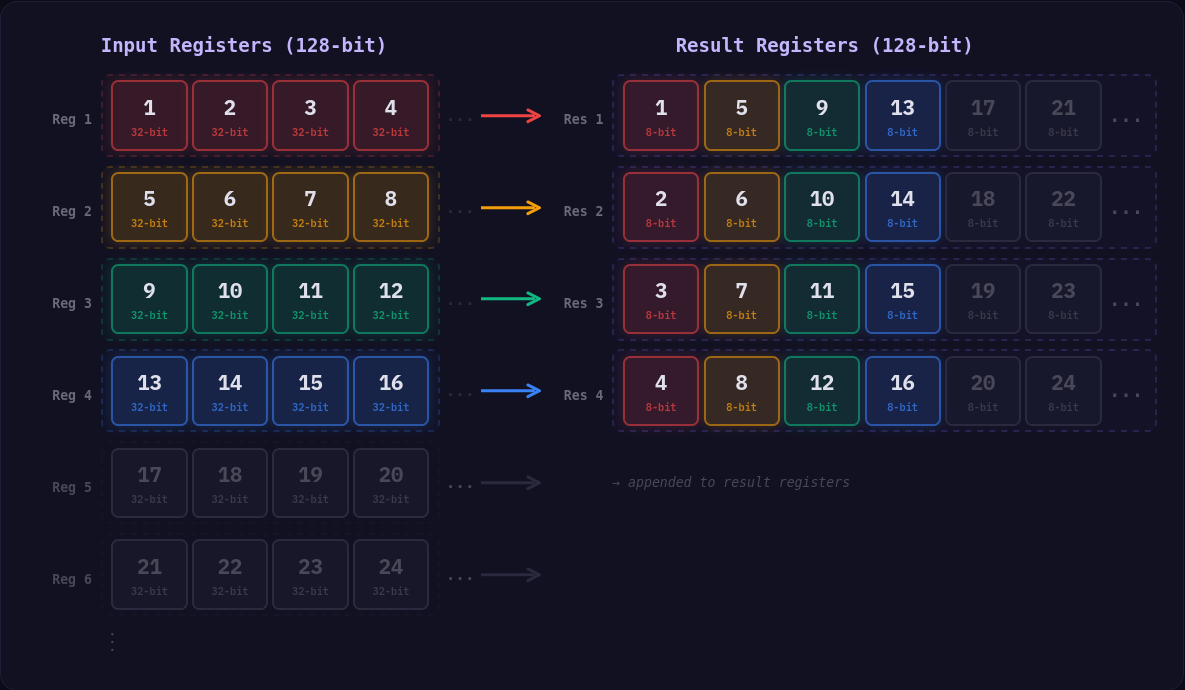
In μpack, however, because the number of integers we want to pack is variable, we have to do something a bit different, because trying to shuffle all of our integers before or after they've been packed in order to use this technique would involve so many additional instructions that it would end up being slower than a naive scalar implementation.
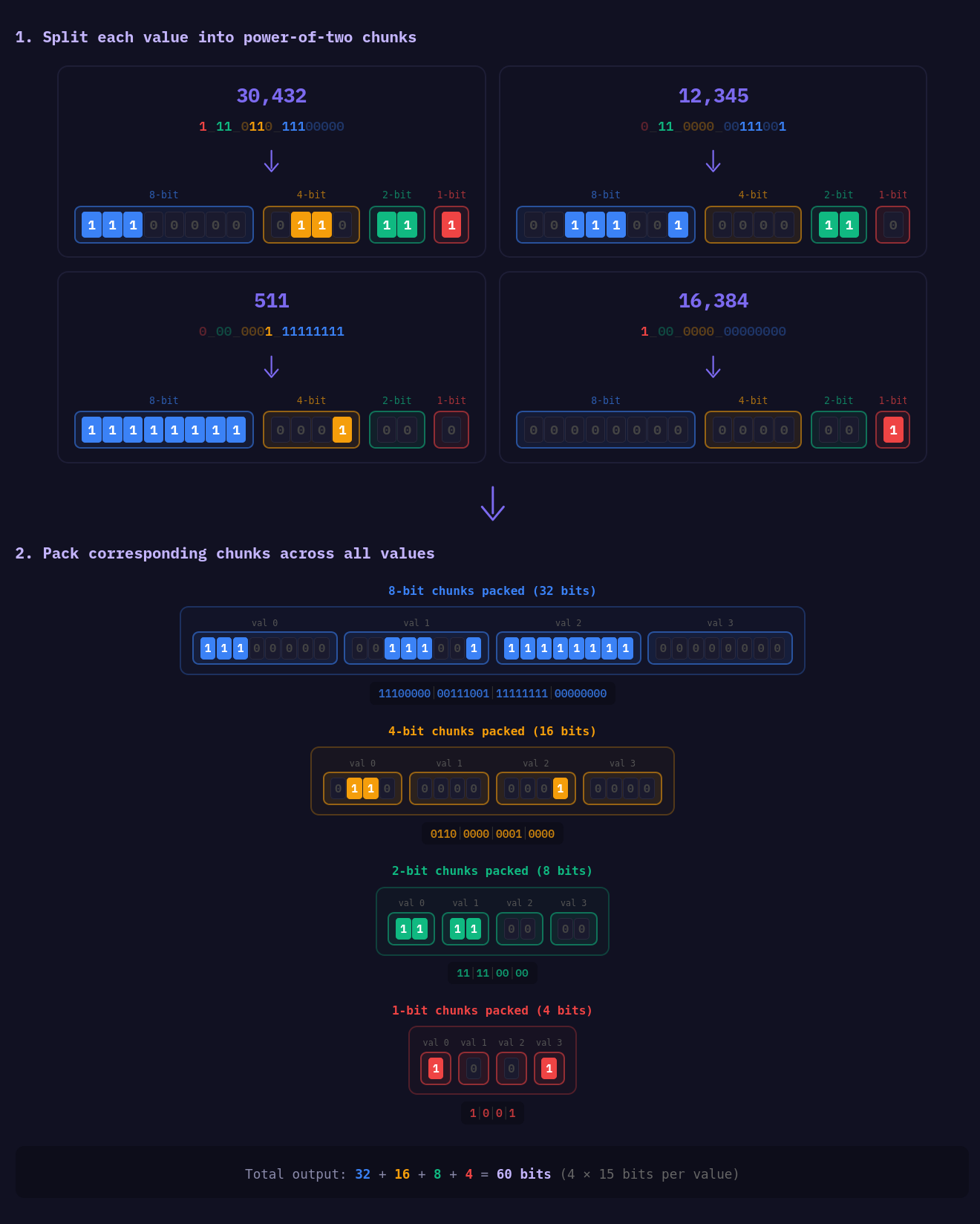
So instead, we split each integer into parts where each "part" is some power of two number of bits, i.e. 1, 2, 4, 8, 16, 32 bitlengths. We do this because all of the SIMD instruction sets we support have some way of converting to and from these different bitlengths efficiently. For example, in AVX2, we have _mm256_packus_epi32 , and on the ARM side, with Neon, we have vqmovun_s32 . Although not all of these instructions have the same result layout, which I will cover a bit later, they can still be used to efficiently convert into these core parts.
As a result, if we take an input integer of 30432 which has the binary representation: 111_0110_1110_0000
We get the following parts:
1110_0000- The first 8 bits of the integer.0110- Followed by the next 4 bits of the integer.11- Followed by the next 2 bits of the integer.1- Finally, the remaining 1 bit of the integer.
We apply this step to every lane in the register and combine each part from each lane to form these compressed blocks, which can be easily done with SIMD and, more importantly, done without any direct data dependencies of the result registers.
The idea is simple in practice, but this approach still requires some implementation nuance, because once we start to implement this algorithm, we run into a few limitations:
- AVX2 machines that do not also support AVX512 have only 16, 256-bit registers. Running out of registers mid-routine would require additional stores and loads, which would significantly reduce performance.
- Neon machines have 32 registers available, but only 128-bit registers, which runs into a similar issue as AVX2 running out of registers.
- Neon has a more limited set of instructions compared to AVX2 and AVX512 in regard to reducing the integer bit-widths, providing only the move-narrow family of instructions, which produce 64-bit result registers, requiring an additional combine instruction to form a 128-bit register again.
- Shuffles are not free, and on some older CPUs like AMD Zen1 and Zen+ microarchitectures, double-pumped AVX2 registers result in more expensive cross-128-bit lane shuffles.
Block size strategy
Given the aforementioned limitations, we can't process all 128 32-bit integers in the block at once, as we'd run out of registers when using AVX2 or Neon. As a result, μpack processes the integers in sub-blocks of 64 integers.
I wish I could say the 64 block size design was the plan from the beginning, but I forgot about the limited registers issues when building the original implementation of this library because I was developing the AVX2 implementation on an AVX512 machine, which provided 32 registers.
Additionally, we implement two versions of the packing routines: one for packing full blocks and another for packing partial blocks. This allows us to remove the additional overhead introduced by maintaining the order of elements when it isn't required.
This results in us creating 12 core routines for packing each "part" per instruction set. And although this results in a significant amount of work implementing the code, it allows us to offer this flexibility without sacrificing performance for full-size blocks.
From there, we implement the 128 integer block processor as a combination of these 64 sub-block routines. Specifically:
- If the size of the output block is less than or equal to
64integers, then we dispatch a single call to thepack_x64_partialfamily of routines. Eliminating the additional processing for the remaining 64 elements in the block that are unused. - If the size of the output block is less than
128integers, then we dispatch two calls, one topack_x64_fulland one topack_x64_partial. We can do this because we know there are at least 64 elements to be packed, which means that the sub-block will never need to be truncated, leaving us with an ordered tail sub-block, which can then be truncated. - Finally, if the output block is exactly
128integers, then we dispatch two calls to thepack_x64_fullroutines.
This strategy helps to minimise the performance loss as we adjust the number of integers packed into the output block.
Serialized layout
The specific compressed layout for a given power-of-two "part" of an integer is relatively simple and does not change across architectures or instruction sets, but does vary between "partial" and "full" sub-blocks and each part's bit-length.
Partial sub-blocks
If it is a partial sub-block, the order of elements is maintained, and the write offset of any subsequent "part" begins at the last byte required to hold the target number of integers.
This potentially introduces some compression efficiency loss for a smaller number of integers due to each power-of-two part taking up the nearest whole byte's worth of space.
For example, a single 32-bit integer 8191 packing to 13 bits will result in 3 bytes being consumed rather than the optimal 2 bytes because 13-bit integers are broken down into 3 parts (8 bits + 4 bits + 1 bit)
Full sub-blocks
When looking at a full sub-block, we do not maintain the original order of elements as an optimisation; we perform vertical packing of each integer "part".
By default, we interleave the integer parts working with 512 contiguous bits, irrespective of whether the underlying hardware is using AVX2 or AVX512, etc... However, the smaller bit lengths are slightly different:
- 4-bit parts use 256 contiguous bits due to the final output being 256 bits in size.
- 2-bit parts use 128 contiguous bits due to the final output being 128 bits in size.
- 1-bit parts maintain their ordering still due to the routine using movemask operations on x86 and an optimised polyfill in ARM-based systems.
The cost of smaller blocks
Although we reduce the amount of compute spent on integers, which will not be included in the output, we cannot totally eliminate this behaviour while also still making use of SIMD. So if we only want to include the first integer in the provided array in the output block, we will still pay for the remaining 63 integers, even if we don't include them in the final compressed block.
To be precise, the efficiency of this implementation looks something like this:
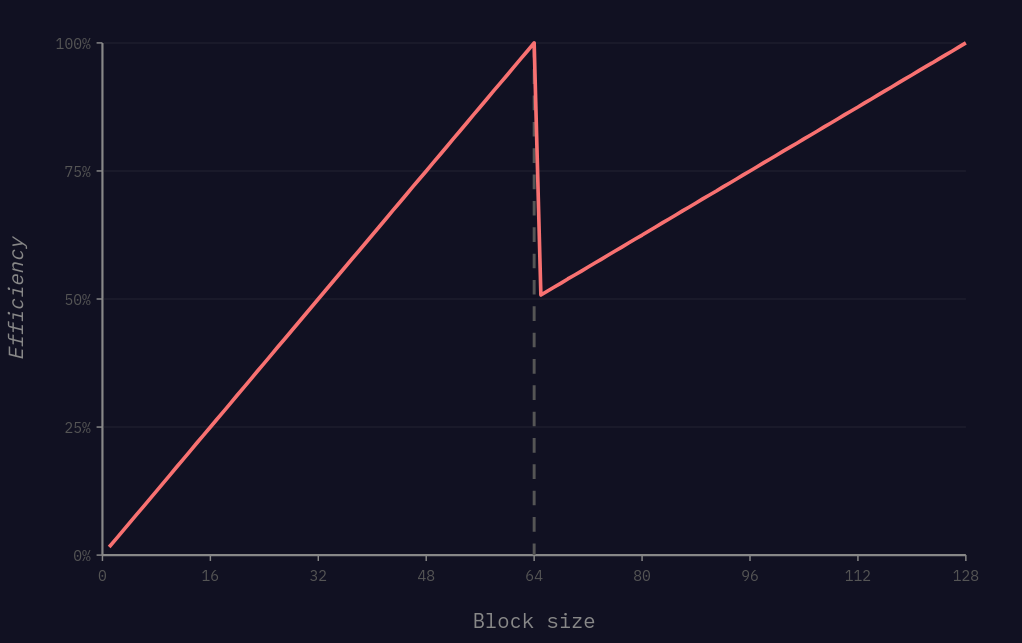
Between 1 and 64 integers, the efficiency scales linearly as the number of elements increases. This is because we are taking a larger percentage of the output, which is calculated at a fixed cost.
Then, once we go beyond 64 integers, we see another drop in efficiency as the system begins to dispatch two sub-block routines. Although this drop is not exactly a 50% reduction because the prior 64 integer sub-block will begin to be processed by the full-block routines, and there is a fixed amount of overhead in calling the routines themselves by doing the lookup.
Implementation
Putting this approach into practice, the resulting Rust code is about 21,000 lines of code and covers Scalar, AVX2, AVX512 and Neon routines for uint32 support and additionally provides delta and delta-1 variants, which are typically used in search engines for posting lists and positions data.
Although describing every optimisation being applied for each different instruction set would be too long for this blog, I wanted to mention a few highlights:
x86's pack family of instructions
On x86 machines with AVX2 or AVX512 enabled, for partial routines, we leverage the pack family of instructions that allow us to pack two sets of registers into a single register, where each lane is half the size of the original.
This instruction works in blocks of 128 bits and interleaves the results alternating between register A and register B in the output. This is an incredibly efficient instruction that makes the shuffling simpler, as we only need 32-bit lanes in the case of packing a 32-bit integer to an 8-bit integer (128 bits -> 64 bits -> 32 bits), or 64-bit lanes in the case of packing 32-bit integers to 16-bit.
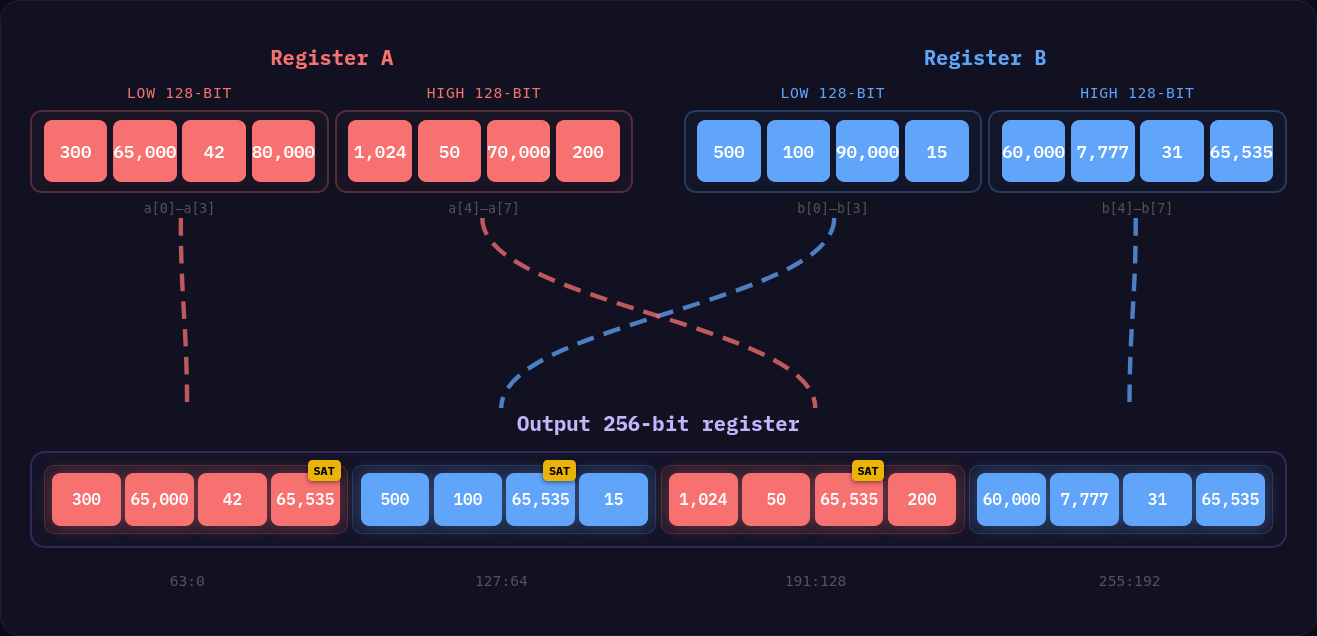
On the flipside, Neon does not have a direct mirror of this instruction, but does provide instructions for converting to smaller integers and then combining the 64-bit output registers back into 128-bit registers, which saves us from shuffling the results, so the performance difference between Neon and AVX2 here is probably a wash outside the need for simply doing more Neon instructions due to the smaller register widths.
#[target_feature(enable = "neon")]
/// Pack the two provide [u32x8] registers to unsigned 16-bit
/// integers in blocks of 128-bits.
pub(super) fn _neon_pack_u32x8(a: u32x8, b: u32x8) -> u16x16 {
let a_lo = vmovn_u32(a[0]);
let a_hi = vmovn_u32(a[1]);
let b_lo = vmovn_u32(b[0]);
let b_hi = vmovn_u32(b[1]);
let r1 = vcombine_u16(a_lo, b_lo);
let r2 = vcombine_u16(a_hi, b_hi);
u16x16([r1, r2])
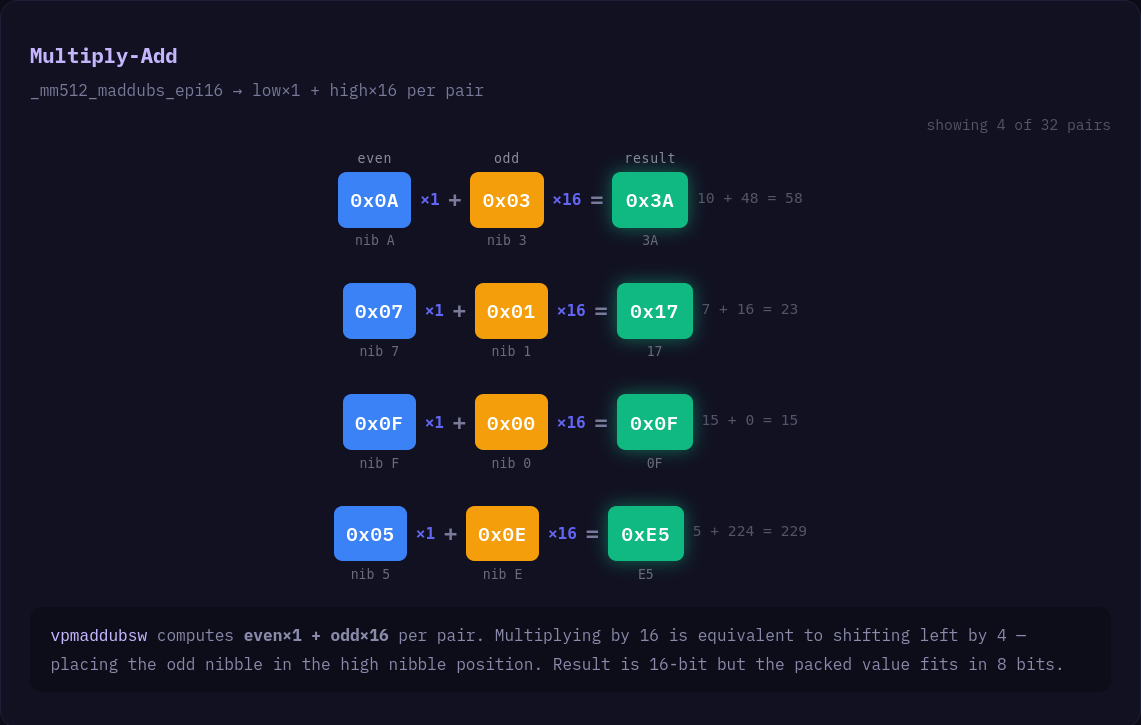
}Using _mm*_maddubs_epi16 to pack nibbles
Packing nibbles while maintaining the order of elements can be tricky because interleaving the elements and then shuffling them on x86 becomes both very complicated and very expensive. Fortunately, we can use this little trick...
Given an ordered set of 8-bit integers, if we interpret that input as 16-bit integers, we can then use _mm512_maddubs_epi16 (Or AVX2 _mm256 equivalent) combined with a mask of 0x1001 . We can combine adjacent pairs of nibbles into a single 16-bit integer that can then be easily converted to 8-bit integers that contain the packed nibbles.

Match block codegen and LUT tables for dispatching
Originally, a match block was used to dispatch a given target bitlength to a packing function, which looked like this:
match nbits {
0 => unsafe { to_u0(output, input, n) },
1 => unsafe { to_u1(output, input, n) },
2 => unsafe { to_u2(output, input, n) },
...
}However, LLVM did not compile this very well, and the resulting ASM was checking nbits 33 times and adding a jump label at each comparison. By replacing the match block with this LUT, the performance improved by about 15-20%, depending on the hardware.
const LUT: [unsafe fn(&mut [u8; X128_MAX_OUTPUT_LEN], &[u32; X128], usize); 33] = [
to_u0, to_u1, to_u2, to_u3, to_u4, to_u5, to_u6, to_u7, to_u8, to_u9, to_u10, to_u11,
to_u12, to_u13, to_u14, to_u15, to_u16, to_u17, to_u18, to_u19, to_u20, to_u21, to_u22,
to_u23, to_u24, to_u25, to_u26, to_u27, to_u28, to_u29, to_u30, to_u31, to_u32,
];
let func = unsafe { LUT.get_unchecked(nbits as usize) };
unsafe { func(out, block, pack_n) };A side effect of this method of dispatching function calls is that it effectively forces a jump to be made with no option for inlining downstream, as you can see by the produced ASM:
upack::uint32::avx512::pack_x128::to_nbits:
mov rax, rdi
lea r8, [rip + .Lanon.4cb93b769a4c3988e8fd210eaf9850ae.7]
mov rdi, rsi
mov rsi, rdx
mov rdx, rcx
jmp qword ptr [r8 + 8*rax]This did cause some issues when moving to the 64-integer sub-block design because previously, for each 128 integer block, we called this function twice and paid the cost of this jump twice, which significantly impacted the overall performance.
The fix for this performance regression was, unfortunately, imperfect, and required creating a separate LUT for the base, delta and delta-1 variants of the unpackers, along with using a small macro to generate the code for dispatching between the partial and full sub-block packers after this jump had been performed.
Optimising bitmask handling in Neon
Neon and ARM in general are not a set of instructions that I am super familiar with and great at optimising, so I was very grateful for a helpful Discord user who pointed me to Niles Selter's blog which specifically goes into optimising moving 64 8-bit elements into a 64-bit mask, it covers some other interesting topics, however I adopted the vectors -> mask and mask -> vectors algorithms. I highly recommend checking it out: https://validark.dev/posts/interleaved-vectors-on-arm/
This change helped close the gap between the μpack algorithm and the simdcomp algorithm. Although we are still slower, I believe there are probably some other optimisations I've missed that would help close that gap some more.
Inspecting the assembly
Using all the small optimisations for different instruction sets, the end result is 132 small SIMD routines for packing and unpacking the 64 integer sub-blocks for each SIMD instruction set. Which means in the actual code, the uint32 packing implementation has 528 separate pack/unpack routines.
As an example, the resulting x86 assembly for packing a set of 64, 32-bit integers to 5-bit integers at once using the partial sub-block strategy, along with the avx512f and avx512bw instructions is:
upack::uint32::avx512::pack_x64_partial::to_u5:
# Load the first 16 elements, skip the next 16
# then load the following 16 elements.
vmovdqa64 zmm0, zmmword ptr [rsi]
vmovdqa64 zmm1, zmmword ptr [rsi + 128]
# Load the permutation mask for correcting the ordering
# of packed elements afterwards.
vmovdqa64 zmm2, zmmword ptr [rip + .LCPI239_0]
# Calculating write offsets
mov rax, rdx
shr rax
# Pack zmm0 with the second set of 16 elements
# and then pack zmm1 with the fourth set of 16 elements
# producing 16-bit integers.
vpackusdw zmm0, zmm0, zmmword ptr [rsi + 64]
vpackusdw zmm1, zmm1, zmmword ptr [rsi + 192]
# More offset calculation
sub rdx, rax
# Pack the two produced registers zmm0 and zmm1
# holding 16-bit integers into 8-bit integers
vpackuswb zmm0, zmm0, zmm1
# Apply the shuffle permutation mask we loaded
# earlier.
vpermd zmm0, zmm2, zmm0
# Select only the low 4-bits of zmm0 and store in zmm1
vpandd zmm1, zmm0, dword ptr [rip + .LCPI239_3]{1to16}
# Use maddubs trick to pack nibbles together while
# producing the correct order of elements.
vpmaddubsw zmm1, zmm1, zmmword ptr [rip + .LCPI239_2]
# Select the remaining 1-bit from the 8-bit integers
vpsllw zmm0, zmm0, 3
# Move the most significant bit (which is our high 1-bit)
# into the result mask.
vpmovb2m k0, zmm0
# Convert 16-bit integers to 8-bit integers via
# truncation and store the packed nibbles
vpmovwb ymmword ptr [rdi], zmm1
# Store the 1-bit mask
kmovq qword ptr [rdi + rdx], k0
vzeroupper
retComments added after getting the ASM using cargo-show-asm
Without the comments, you can see that this routine is incredibly compact while allowing us to fully leverage the wider 512-bit register widths without requiring larger block sizes like simdcomp:
upack::uint32::avx512::pack_x64_partial::to_u5:
vmovdqa64 zmm0, zmmword ptr [rsi]
vmovdqa64 zmm1, zmmword ptr [rsi + 128]
vmovdqa64 zmm2, zmmword ptr [rip + .LCPI239_0]
mov rax, rdx
shr rax
vpackusdw zmm0, zmm0, zmmword ptr [rsi + 64]
vpackusdw zmm1, zmm1, zmmword ptr [rsi + 192]
sub rdx, rax
vpackuswb zmm0, zmm0, zmm1
vpermd zmm0, zmm2, zmm0
vpandd zmm1, zmm0, dword ptr [rip + .LCPI239_3]{1to16}
vpmaddubsw zmm1, zmm1, zmmword ptr [rip + .LCPI239_2]
vpsllw zmm0, zmm0, 3
vpmovb2m k0, zmm0
vpmovwb ymmword ptr [rdi], zmm1
kmovq qword ptr [rdi + rdx], k0
vzeroupper
retSynthetic Benchmarks (uint32)
A custom benchmark runner is available within the μpack repository. The runner is designed to provide a slightly more realistic benchmark of the routines with data you would find when implementing a database or search engine.
Specifically, it generates input data that attempts to mirror a search engine's posting list: you start with an initial integer value, followed by a monotonic increase in the doc IDs within the block.
The runner allows you to configure:
- The number of sample blocks to generate per timing measurement.
- The maximum gap between consecutive integers in the block.
- The maximum bitlength of integers to produce, by default, this value is set to
26, which is realistically the largest doc ID you are likely to get in a single search engine segment from Lucene or Tantivy (67 million docs) - Per routine benchmark duration, aka how long to keep generating sample data, then measuring until the time has elapsed. Typically, the longer this value is, the more stable and consistent your results will be.
- The RNG seed for generating the sample data.
As always, this runner, while it attempts to be more accurate than a microbenchmark, is still a synthetic benchmark; you should always compare these implementations using the actual data you expect to be processing, and take the results with a pinch of salt.
You can run the benchmark runner using the Justfile recipe just bench and the results are for the uint32 data type.
Notes on Neon results
As mentioned earlier, the Neon implementation lags behind the simdcomp algorithm, which I believe is down to two factors:
- There are probably some niche optimisations for Neon that can be applied.
- Using 128-bit registers, the μpack algorithm requires more instructions in order to compress and decompress the data.
That said, this algorithm should catch up and surpass the simdcomp version as newer ARM-based server CPUs adopt SVE2 and wider registers. We're already starting to see these chips appear on Google Cloud Platform and Microsoft Azure.
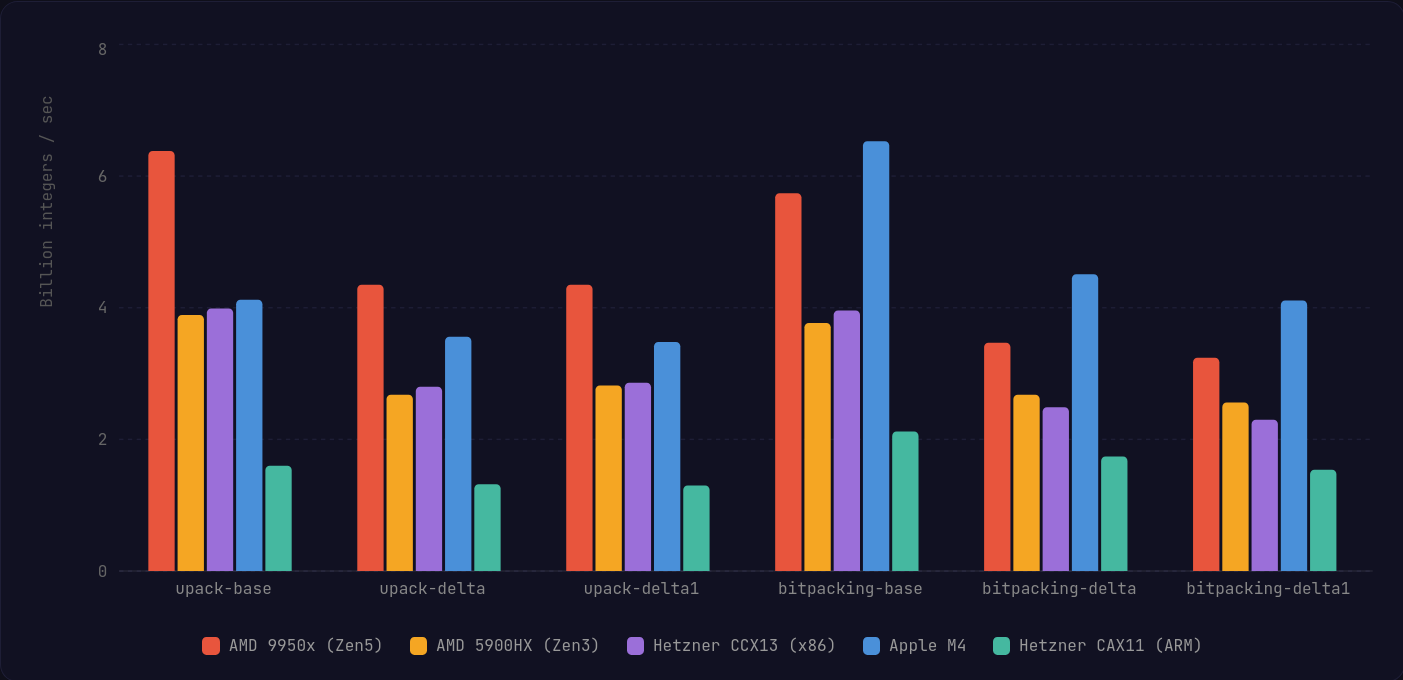
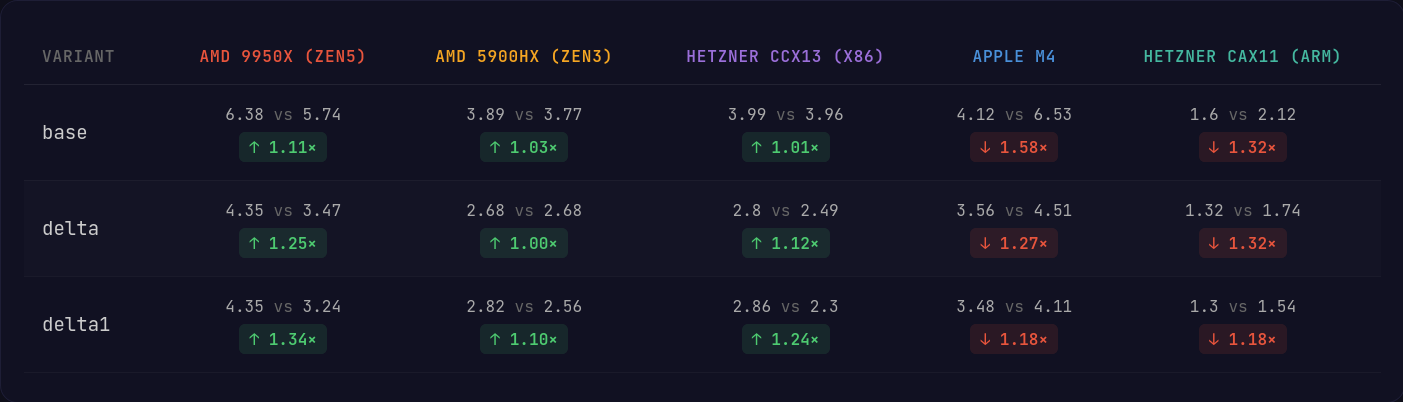
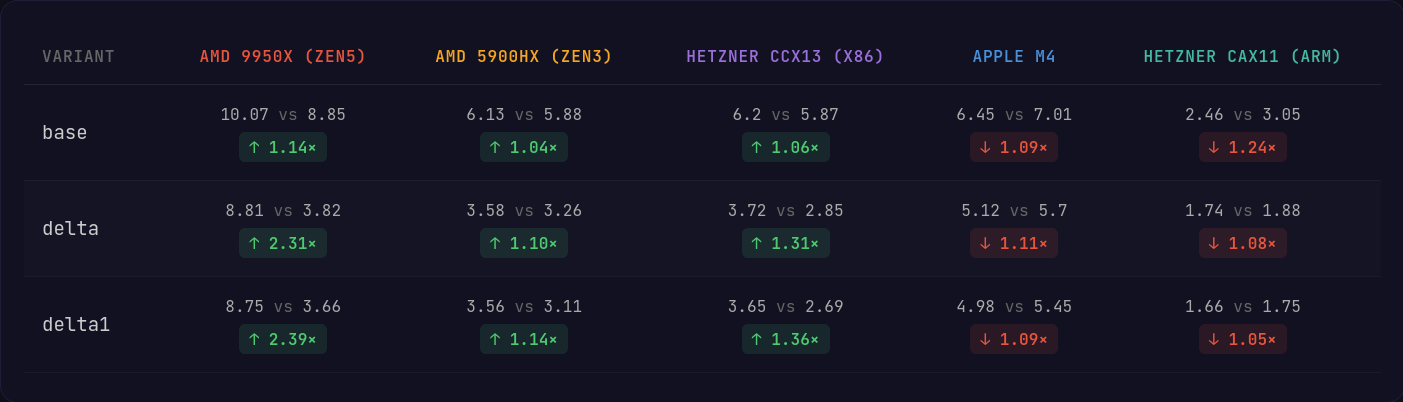
Compression
Overall, x86 sees a minor improvement on average across all variants when the AVX2 instruction set is supported by the processor. On the AVX512 machine using the Zen5 microarchitecture, we can really see where the wider registers and more versatile instructions can push the performance forward.
Unfortunately, we take quite a large performance hit on Apple Silicon with the Neon implementation; that being said, Apple Silicon is significantly more powerful than the normal Graviton and Ampere CPUs you see on the server side and on weaker hardware, we see the gap close a bit more.
Decompression
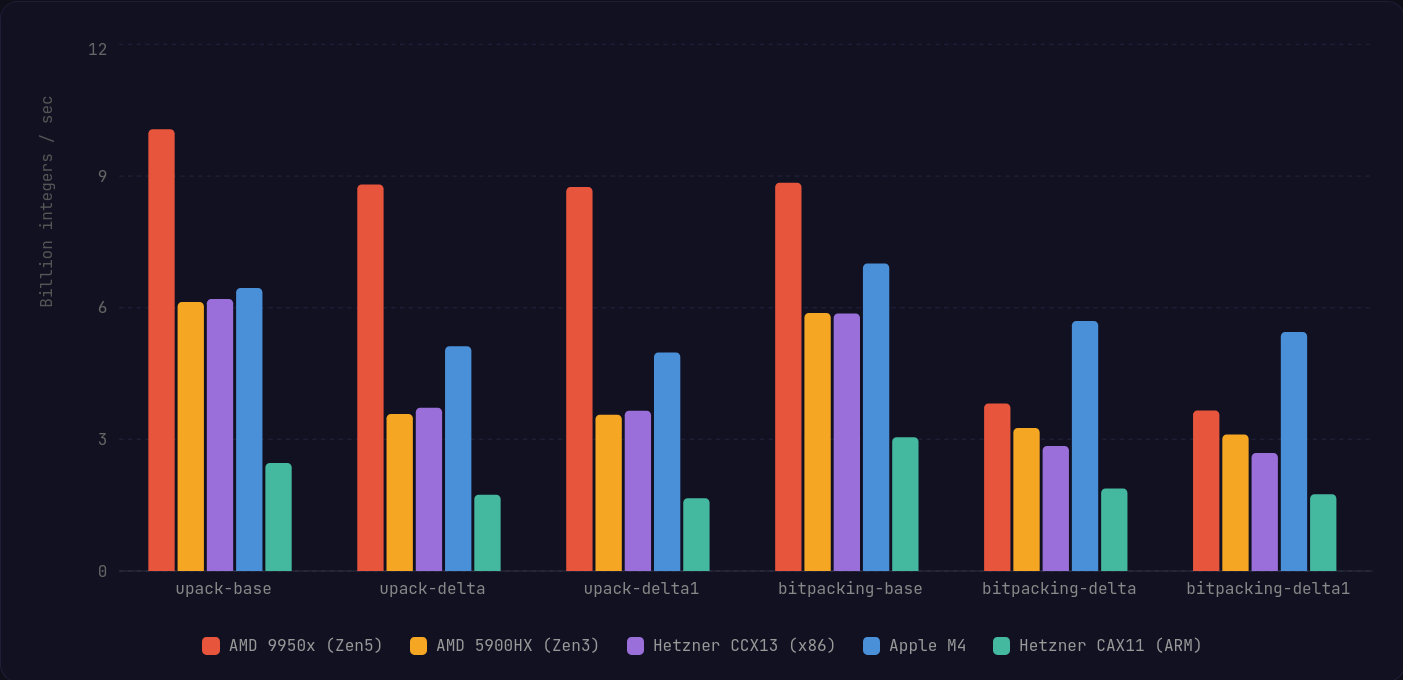
Decompression on x86 is where we see the greatest gains, particularly on AVX512, which can easily cast bitmasks to populated registers and decode delta encoded integers in the blocks with far fewer instructions and without additional shuffles.
On the ARM side, the Neon implementation closes the gap significantly to where I'd say it is probably not noticeable to most applications.
Final Thoughts
Overall, I think the algorithm makes acceptable tradeoffs around performance while offering greater flexibility, allowing implementors to achieve a greater compression ratio than a variable-byte strategy like StreamVByte that is typically used for blocks of integers that are not exact sizes.
In the long term, as ARM-based CPUs continue to evolve, we can see it close the gap and surpass simdcomp in performance.
I did fork and modify Tantivy to test out how the performance gains affect performance in a broader scope; however, at the time of writing, my Tantivy fork introduced a bug during merging segments (unrelated to μpack itself), which made running the benchmarks unreliable for others to run, I plan to share those separately when I get time to fix the Tantivy fork.
This library is actually one of two integer compression libraries I'm working on, but as the second library depends on the flexible block sizes, it seems logical to split this library out into its own crate and publish it separately, so I look forward to the second algorithm, which should provide another interesting set of improvements in the integer compression space.
👋 Thanks for reading. I hope this blog was at least somewhat interesting, and you now have a basic understanding of how both simdcomp and μpack work.
If you want to contribute to the project, the source code is available at https://github.com/lnx-search/upack. Any optimisations welcome, provided it does not break the data layout, and it is reproducible.
Cool visual: Compression vs StreamVByte
One of the benefits of allowing variable-size output blocks is the stronger compression ratio when compared against the more traditional byte-wise algorithms like StreamVByte.
If you're wondering why this is at the end, it is because Ghost (the CMS I use for this blog, breaks mobile views when rendering embedded iframes.)