SurrealDB is sacrificing data durability to make benchmarks look better
SURREAL_SYNC_DATA=true in your environment variables otherwise your instance is NOT crash safe and can very easily corrupt.If you're familiar with Rust or follow what new hype databases are gaining a following, you might have heard of SurrealDB, a jack-of-all-trades database that does it all... So they say.
SurrealDB is the ultimate database for tomorrow's serverless, jamstack, single-page, and traditional applications.
What their marketing sells seems like a great tool, but it looks like their talk is going far beyond the tool they actually have and in their haste, they are failing to do the most important job of the database: actually keeping data safe.
Background
In the process of writing another blog post that aimed to test how well new startup databases of various types actually keep your data safe and durable compared to the old reliable options, and testing my own datastore durability.
In order to collect a set of tests and edge cases, I often like to dig through prior issues and discussions to look for various bugs or edge cases with the file system that can often cause your data to disappear if you're not careful.
A great example of this is the "fsyncgate 2018" issue in PostgreSQL, in which Postgres would incorrectly retry fsync calls upon error, which could result in Postgres thinking a write is durable when, in fact is not and has been silently dropped by the OS. If you're looking for an interesting read, have a look at the details in https://wiki.postgresql.org/wiki/Fsync_Errors and the linked articles.
https://dl.acm.org/doi/fullHtml/10.1145/3450338
Unanswered corruption questions
During this research step, I stumbled upon this discussion question in the SurrealDB GitHub, where they describe that their SurrealDB instance became corrupted after a power outage. This discussion issue has had no response from the developers as of the time of writing.
🤔Well, that is weird. I think most people would expect their database to be durable once it tells them the operation is complete. I certainly wouldn't expect a power outage to cause total failure.
Looking at their Discord, I can see a few mentions from users where their database has corrupted mysteriously, none of which seem to have gotten answers or fixes.
The issue mentions that they found out they need to set some environment variables to ensure durability, in particular, the SURREAL_SYNC_DATA environment variable. But surely this should not need to be explicitly enabled in order to keep your data safe... right?
Digging into Surreal's code
Quick crash course! Surreal internally wraps around several KV stores, including TiKV, which is what they recommend for an HA setup, RocksDB for embedded or single-node applications and SurrealKVwhich is their home-grown experimental implementation.
Since all these issues seem to mention RocksDB, we're going to focus on that, RocksDB in particular is fairly notorious for being a very powerful, but difficult to configure, and a lot of care needs to be taken to ensure your data is durable as by default it does not flush and sync data to disk on each operation.
Digging into surrealdb/crates/core/src/kvs/rocksdb/mod.rs we can find where they define their RocksDB options. I've stripped out the irrelevant options and just highlighted the bits that might impact the durability of data on disk so it is easier to digest.
In the above snippet, there isn't anything wrong here, as the comment correctly notes, they want to use fdatasync over fsync, which is perfectly valid most of the time, as it is rare that you actually need the metadata fsync updates (i.e modified timestamps) that fdatasync does not in order to ensure the durability of data.
But this is where things start to get weird...
What this block is attempting to do is check if the user has set SURREAL_ROCKSDB_BACKGROUND_FLUSH (which defaults to false).
If they have, create a background thread that calls flush_wal every ROCKSDB_BACKGROUND_FLUSH_INTERVAL milliseconds (defaults to 200) in addition to this, if SURREAL_SYNC_DATA is true, the WAL will have a fsync/fdatasync call issued to the OS after each flush, ensuring durability, but this is not done by default.
Entertainingly, they appear to have a bug in their code where the comment says they wish to only flush the WAL manually, but in the code itself, they set it to be done automatically on every operation by default.
In the end, this block is (currently) just checking if flush_wal should be called manually in a background thread every couple of milliseconds, or if rocks should automatically flush to the OS buffers during each write, the key thing to emphasise here is that this is not going directly to disk, the OS might hold that data in memory, and this is why an fsync or fdatasync call is needed to ensure dirty pages get written to the underlying storage.
bytes_per_sync and wal_bytes_per_sync options in RocksDB to ensure durability is incorrect? This is because internally it uses sync_file_range which which does not correctly ensure data is durable and is explicitly called out in the Kernel docs. This can be a common pitfall, for example, Sled previously made this assumption and has an open issue; however, I cannot see any use of sync_file_range anymore, so this may be fixed now.I've just touched on the need for a fsync or fdatasync call being needed before you can safely say to the user that their data is durable, but how do you do this with RocksDB?
The docs blur the line between flushing to the OS and actually issuing a fsync. The only option I can find that explicitly declares that it will issue one of these calls before returning is WriteOptions.sync = true So let's see if Surreal does this, we can look for WriteOptions from the rocksdb crate to find where they're initialising the transaction.
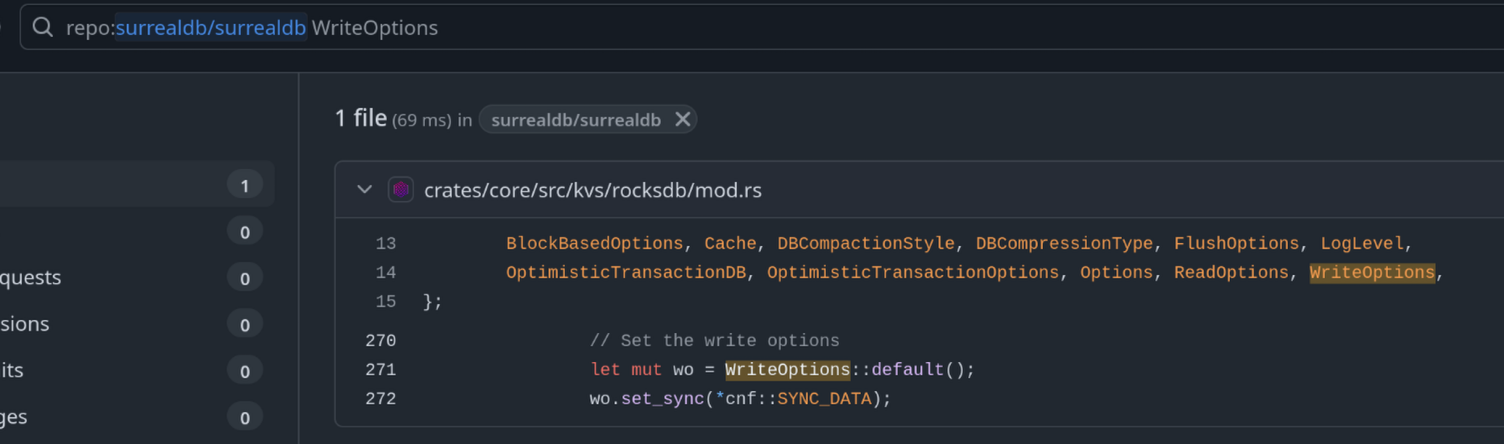
The code is located within the transaction function and the full block is:
Other than some interesting unsafe being used and a very liberal use of unhelpful comments, we can see the only option they set on the write options is:
wo.set_sync(*cnf::SYNC_DATA);
😕 Okay, we've confirmed that now, if our transaction wants to actually be durable, we are at the mercy of whatever SURREAL_SYNC_DATA is set to, and that is an issue.
Why is that an issue, you ask? because this variable defaults to false , and there is zero warning of this behaviour in the documentation. In fact, the only mention of SURREAL_SYNC_DATA is a single field in an HTML table, and this field does not even contain a warning that having this value false will result in your data potentially not being crash safe.
In fact, even if you set all those other RocksDB environment variables, your data is still not safe unless you set this variable to true.
Why you actually need fsync.
I know I've talked for ages around fsync and fdatasync being needed to ensure durability, but if you haven't worked much with the file system or tried to ensure the durability of files, you might not understand quite why you need to call fsync or fdatasync. So let's go through a quick summary of some of the issues.
A simple file write
If I have some data that I want to write to a file, when I ask the OS to write my buffer to the file, the OS will usually copy my buffer into its own buffers (commonly called the page cache, file cache, etc...) it will tell me everything is done before it actually writes my data to the underlying storage. It's important to note, future reads or writes will still be able to see the change we've just made, provided they are not using O_DIRECT which bypasses the OS's own cache/buffers.
Why do this? The OS will try its best to optimise the IO you are performing. If it were written to disk every time, most applications would likely see much lower throughput and result in higher IO amplification because the OS is likely going to need to issue lots of small writes. If we instead use a cache and buffer the changes, we can then do a single larger write further down the line, improving our write throughput in most applications that are not strictly aware of the IO they're performing.

This caching behaviour also helps improve read performance by preventing duplicate or repeated reads from hitting the disk multiple times. This is why, if you read the same small file over and over again, you might see numbers like 30GB/s throughput!

The issue this buffering creates
While this behaviour is great for a lot of reasons, it causes us issues if we want to ensure that when we make a change to a file, the data gets to the disk and won't disappear if we lose power, or even if the next flush errors! (read: https://wiki.postgresql.org/wiki/Fsync_Errors I promise it is interesting.)
Now the OS knows that this is a common issue, and provides us with a few syscalls in order to tell it, "Hey, I really need to make sure this data is durable, please make sure it has been written to disk." On Linux, this is provided by the fsync(2) and fdatasync(3p) syscalls; there is also sync_file_range(2), as I've mentioned earlier. However, this has several issues which make it not suitable to use.
However, you need to call these explicitly; you cannot assume your data is safe once you've passed your buffer to the OS.
Why default to sync=false ?
The answer to this is simple: not forcing a flush to disk results in faster writes, but you give up all your durability guarantees in exchange for more performance. In some ephemeral applications, this might be perfectly valid, but it is absolutely not okay here, and the SurealDB team should (and probably do) know better.
This is actually not the first time a database has advertised that they have some given performance and then, in reality, turn out to be giving up the durability guarantees. MongoDB was notorious for this when it was revealed that they were returning a successful response to the user after writing to memory only.
Clear awareness of durability being off by default.
Just above, I alluded to the SurrealDB team knowingly making durability an opt-in feature, and this seems to be the case as their home-grown SurrealKV implementation handles the SYNC_DATA flag as:
Which clearly signals that data is not durable unless SYNC_DATA is true, and yet they choose to default to false despite multiple users running into corruption.
Even in the SurrealKV library, they default to not calling fsync/fdatasync before returning a successful response to the user. In fact, in this situation, SurrealKV will never try and issue a fsync/fdatasync unless you later issue a transaction that does select Durability::Immediate which could mean your data never even touches your disks!
Honestly, this sort of thing drives me absolutely nuts. It is one thing to have it off by default, but it is another thing to also give the user zero warning about this behaviour. The only thing you gain from doing this is making your benchmarks look better than they actually are if a user is testing the performance, or you're making numbers look good on a blog post.
Bonus point on benchmark dishonesty
It took Surreal quite a while to release their own benchmarks; they weren't particularly interesting, but I do find it quite funny that when compared against MongoDB and ArangoDB, they force Mongo to ensure data is durable, but Surreal and Arango do not. 🙃
To be clear, in their MongoDB configuration, they specify the write configuration as:
So in this case, they are clearly aware of the memory buffering in Mongo and explicitly want the results to only be successful once it is safely on disk and durable, but don't do the same for their system or Arango.
I will equally say that ArangoDB should also not be skipping durability checks by default, but I guess the allure of VC money over correctness goes over their heads.
Improving
In summary, if you are a SurrealDB developer, you must either make SYNC_DATA true by default, or make it screamingly obvious that if a user does not do it themselves, they might lose all their data.
I would go for the former because users rarely know when they should or should not play with options like this, and defaults should try to prevent users blowing their own legs off.
There is also zero reason to be benchmarking yourself and others without ensuring durability when 99.999% of users want their data to be durable.
If you are a user already using SurrealDB and using one of either SurrealKV or RocksDB backends, please ensure you have the SURREAL_SYNC_DATA environment variable set to true Otherwise, the next time your system restarts might be the last time you see your data. 🙂
If you are using TiKV, you are probably fine; by default, they ensure durability, and I don't think there is a way to misconfigure that outside of explicitly telling it not to flush the WAL and ignore the massive warnings it gives you.
Post rant message
👋Hi there, it's been a while since I last wrote anything on my blog, and I'm hoping to start getting into a more regular rhythm with outputting a few interesting posts every year, hopefully looking into more depth at various file system and IO-related issues.
Hopefully next post will either be around testing how well new databases handle file system errors and edge cases, or a look at some of the challenges of ensuring your data isn't corrupted when implementing a database buffer pool or persistence layer without tanking performance.